Description
Offline Translation is a fully on-device iOS app that translates text embedded in photos using Apple-native models as well as open-source models for OCR and multilingual machine translation. The app supports multiple pipelines—ranging from modular OCR + translation systems to end-to-end vision-language models—to benchmark translation quality across both high-resource and low-resource languages. All translation and inference happens on-device, without relying on cloud services or internet access.
Use Case
This app is built for travelers or users in low-connectivity environments who need fast and private translation of real-world text, such as road signs, menus, forms, or instructions. It functions offline, offering immediate utility in airports, remote regions, or while roaming internationally. The app also serves as a technical reference implementation for mobile AI deployment.
Market Comparison
Apple and Google both offer offline translation apps for IoS that rely on downloadable language kits. However, their OCR and translation components are not customizable, and language coverage is limited. Offline Translation investigates whether an open-source pipeline can surpass their translation quality and/or coverage.
Key Research Questions
- Can open-source pipelines outperform Apple Translate?
For languages already supported by Apple, can a custom pipeline—using better OCR or translation models—offer improved accuracy
- Can we support languages that Apple does not?
Apple's OCR does not support scripts such as Tamil. Can other models provide working translation pipelines for these under-served languages?
Commercial Feasibility
1/5 – This app is not intended as a commercial product. Apple and Google's first-party distribution advantages make competition impractical. Instead, Offline Translation is a research vehicle to explore the performance and deployment limits of modern multilingual models on mobile devices.
Technical Goals
- Baseline: Reproduce the functionality of Apple's native Translate app using only system-provided frameworks (Core ML, Vision, Natural Language, and Translate APIs).
- Augmentation: Improve OCR and translation quality by integrating fallback local models—such as Google MLKit for OCR and Meta's M2M-100 (418M) for translation—when Apple's stack fails or lacks language support.
- Exploration: Investigate the viability of running compact vision-language models (e.g., MiniGPT-style) that perform image-to-translation in a single step.
- iOS Development: Implement the app entirely in Swift, deepening familiarity with Apple's mobile SDKs, including model integration and on-device inference.
- Local Model Deployment: Explore the practical constraints of edge deployment—converting models (e.g., via
coremltools), managing memory footprint, tuning latency, and leveraging Apple hardware accelerators like the Neural Engine (ANE).
Architectures Compared
The app is implemented in three interchangeable pipelines, all with the same UI:
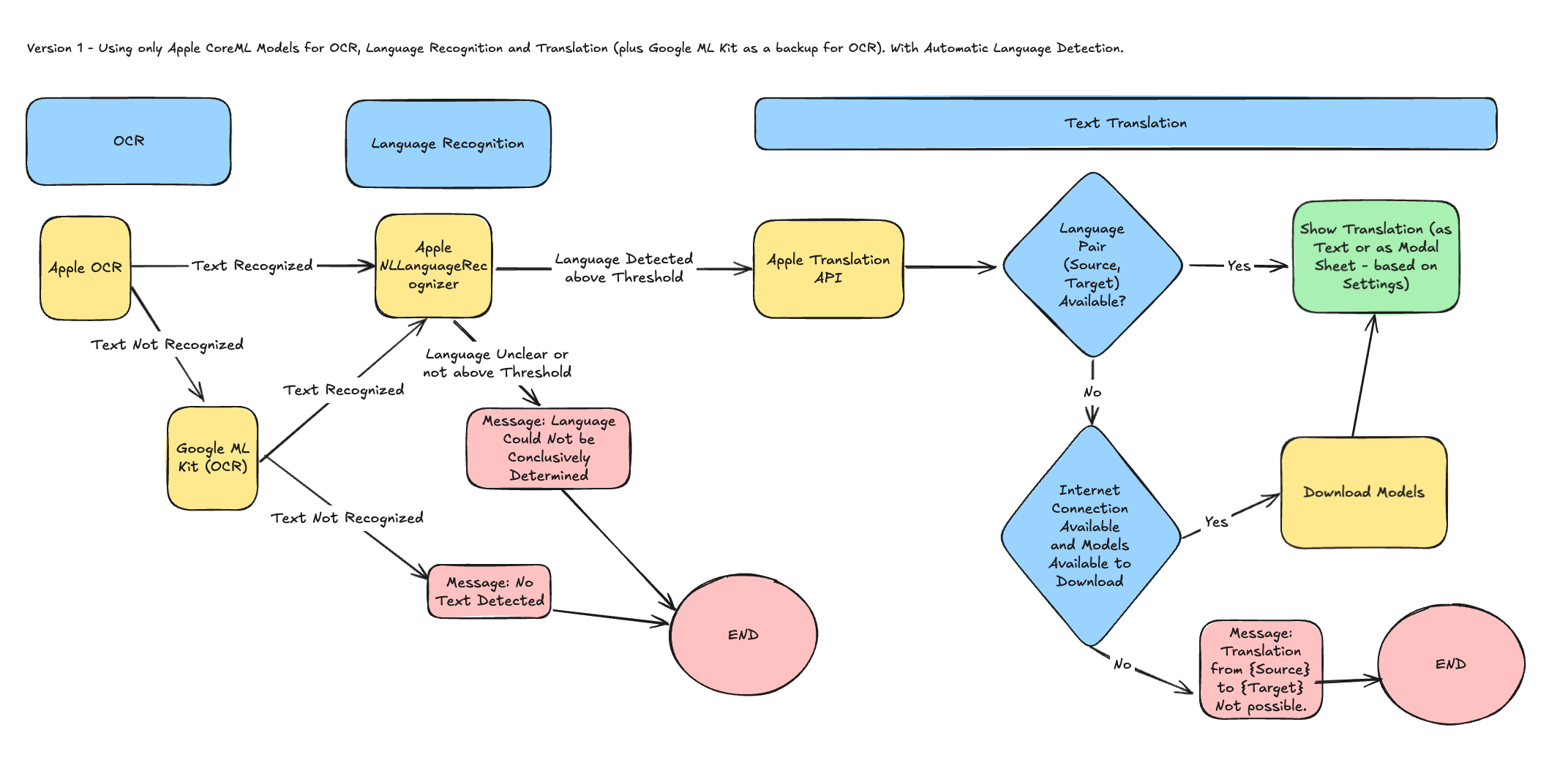
- Apple-native pipeline
A baseline using Apple's own APIs for OCR (Vision), language detection (Natural Language), and translation (Translate). This pipeline serves as the control group to benchmark against.
- Hybrid pipeline
Primarily uses Apple frameworks, but selectively falls back to third-party local models in failure cases. For example, if Apple Vision fails to detect text or the language is unsupported, the app invokes Google MLKit for OCR and a local copy of Meta's M2M-100 (418M) for multilingual translation.
- End-to-end vision-language model
An experimental pipeline that uses a single compact vision-language model (e.g., MiniGPT-style) to go directly from an image to a translated string, bypassing modular components. Used to explore next-generation model architectures.
Choice of Models
Each pipeline uses models selected for their runtime performance, license compatibility, and support for low-resource languages:
- Apple-native pipeline:
- OCR: VNRecognizeTextRequest (Vision)
- Language Detection: NLLanguageRecognizer
- Translation: Apple Translate API
- Hybrid pipeline:
- OCR: Primary – Apple Vision; Fallback – Google MLKit (for multilingual printed text)
- Language Detection: Primary – Apple Natural Language
- Translation: Primary – Apple Translate; Fallback – Meta M2M-100 (418M), running via Core ML with int8 quantization for near real-time performance
- End-to-end vision-language model:
- Model: A compact, quantized variant of a MiniGPT-style model (under 3B parameters)
- Functionality: Direct image-to-translation inference; slower but used to evaluate unified multimodal workflows
Model Choice Tradeoffs
This project considered several open-source alternatives before selecting the final models for each component. The selection was based on technical feasibility, mobile optimization potential, and ability to support low-resource languages:
- M2M-100 (418M) was selected for fallback translation in the hybrid pipeline due to its:
- Direct many-to-many translation across 100 languages (no pivoting through English)
- Strong performance on both high- and mid-resource language pairs
- MIT license (suitable for commercial use)
- Feasibility for real-time execution with quantization (under 1 GB memory footprint)
- NLLB-200 (600M) was evaluated for translation but ruled out for production use due to its non-commercial license (CC-BY-NC 4.0) and larger memory footprint (~1.3–2.5 GB). It remains a useful benchmark for research purposes.
- MarianMT and OPUS-MT models were also considered for translation. While lighter in size, they often underperform M2M-100.
- Tesseract OCR and PaddleOCR were reviewed as alternatives to Apple Vision and MLKit. However, they were deprioritized due to lower mobile inference performance and less seamless integration with iOS. PaddleOCR remains under consideration for future low-resource script support.
- MiniGPT-4, BLIP-2, and other open multimodal models were explored for the end-to-end pipeline. While promising, these models remain too large (>3–7B params) for smooth mobile inference today. Experimental quantized versions are included to evaluate future viability as devices become more capable.
- Gemini Nano (https://deepmind.google/technologies/gemini/nano/) is one of the most promising, highly capable on-device models. However, at the moment it is not available for use on iOS devices.
- Imp (2024) – A recently released mobile-optimized multimodal language model (https://imp-vl.github.io/) that achieves GPT-4V–level performance with only 3B parameters. This makes it a strong candidate for future on-device image-to-text translation without separate OCR.
Evaluation Methodology
To assess the performance of each pipeline, we will conduct evaluations focusing on both individual components and the overall system:
Component-Level Evaluation
- OCR Accuracy:
- Metrics: Character Error Rate (CER) and Word Error Rate (WER).
- Test Set: A diverse set of images containing various scripts (Latin, Cyrillic, Devanagari, etc.) under different lighting conditions.
- Language Detection:
- Metrics: Accuracy and F1 Score.
- Test Set: Text snippets in multiple languages, including low-resource languages.
- Translation Quality:
- Metrics: BLEU and METEOR scores.
- Test Set: Standard translation benchmarks like WMT datasets, focusing on low-resource language pairs.
System-Level Evaluation
- End-to-End Accuracy:
- Metrics: Overall translation accuracy from image input to translated text output.
- Test Set: Real-world images with textual content in various languages.
- Performance Metrics:
- Latency: Time taken to process an image and produce the translation.
- Resource Utilization: CPU and memory usage during processing.
Results & Learnings
(In progress)